Docker持久化存储与数据共享 构建可靠的数据处理与存储服务
在现代容器化应用部署中,Docker以其轻量、高效和可移植性成为主流选择。容器本身具有“无状态”的特性,这意味着默认情况下,容器内部创建或修改的数据会随着容器的删除而消失。这对于需要持久保存数据的应用(如数据库、文件存储服务、数据处理流水线)来说是不可接受的。因此,理解并正确实施Docker的持久化存储和数据共享机制,是构建稳定、可靠的数据处理和存储服务的关键。
一、为何需要持久化存储与数据共享?
- 数据持久性:确保应用数据(如数据库文件、用户上传内容、日志文件)在容器重启、更新或迁移后依然存在。
- 数据共享与协作:允许多个容器(例如,一个Web应用容器和一个数据分析容器)安全、高效地访问和操作同一份数据集。
- 数据备份与恢复:将数据存储在容器外部,便于进行备份、迁移和灾难恢复操作。
- 性能与解耦:可以将数据存储与容器计算生命周期解耦,使用高性能存储方案,而不受容器运行的影响。
二、Docker持久化存储的核心机制
Docker主要提供了三种数据管理方式,以实现不同程度的持久化:
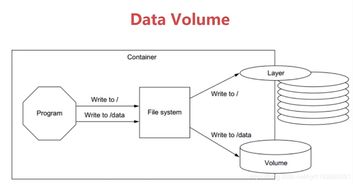
- Bind Mounts(绑定挂载):
- 原理:将宿主机文件系统上的一个特定目录或文件直接挂载到容器内部。
- 特点:高性能,完全访问宿主机文件系统;数据存储在宿主机的明确路径下,易于宿主机工具访问和管理。
- 用例:开发环境(挂载源代码)、需要与宿主机共享配置文件或特定数据。
- 命令示例:
docker run -v /host/data:/container/data my-app
- Volumes(数据卷):
- 原理:由Docker自身管理的存储单元,存在于宿主机文件系统中,但位置通常由Docker控制(如
/var/lib/docker/volumes/)。
- 特点:Docker CLI和API提供了专门的管理命令(
docker volume create/ls/rm);生命周期独立于容器,是Docker中首选的持久化方法;支持卷驱动,可以实现网络存储(如NFS, AWS EBS)。
- 用例:生产环境数据库数据存储、需要在多个容器间共享的数据。
- 命令示例:
docker run -v my-data-volume:/var/lib/mysql mysql
- tmpfs Mounts(临时文件系统挂载):
- 原理:将数据存储在宿主机的内存中,而非磁盘上。
- 特点:速度极快,但容器停止后数据即消失;不占用磁盘空间。
- 用例:存储临时、敏感或不需要持久化的数据(如会话缓存)。
三、实现容器间的数据共享
构建数据处理和存储服务时,经常需要多个服务组件协同工作。数据共享是实现这一目标的基础。
- 通过数据卷(Volumes)共享:这是最推荐的方式。可以创建一个命名的数据卷,然后在多个容器的
docker run命令或docker-compose.yml文件中指定挂载同一个卷。 - 场景:一个
Nginx容器提供静态文件服务,这些文件由一个Node.js应用容器生成并放入共享卷。
- 通过绑定挂载(Bind Mounts)共享:多个容器可以绑定挂载到宿主机的同一个目录。虽然直接,但在生产环境中需谨慎管理宿主机目录权限和路径。
- 容器间同步:对于更复杂的场景,可以使用诸如
rsync、分布式文件系统(如GlusterFS, Ceph)的卷驱动,或者利用应用层的数据同步协议。
四、构建数据处理与存储服务的最佳实践
- 为数据选择正确的存储类型:
- 数据库数据:务必使用数据卷(Volume),确保数据的独立性和可备份性。考虑使用支持快照和复制的云存储卷驱动(如AWS EBS, Azure Disk)。
- 配置文件:可使用绑定挂载或只读数据卷,便于在宿主机修改配置而无需重建镜像。
- 应用日志:建议使用绑定挂载到宿主机标准日志目录(如
/var/log),或使用日志驱动(如json-file,syslog,fluentd)将日志直接发送到中央日志系统,避免日志填满容器存储。
2. 使用Docker Compose编排多服务数据流:
在docker-compose.yml中明确定义卷和服务间的依赖关系,使得数据处理流水线(如:数据摄入 -> 处理 -> 存储 -> 可视化)的搭建一目了然。
`yaml
version: '3.8'
services:
database:
image: postgres
volumes:
- db-data:/var/lib/postgresql/data
processor:
build: ./processor
volumes:
- db-data:/mnt/data:ro # 以只读方式访问数据库数据卷
- processed-data:/output
api:
build: ./api
volumes:
- processed-data:/data:ro # API只读访问处理后的数据
volumes:
db-data:
processed-data:
`
- 实施数据备份与恢复策略:
- 定期备份数据卷内容(可使用
docker run --rm -v volume_name:/volume -v /backup:/backup alpine tar czf /backup/backup.tar.gz -C /volume .)。
- 在云环境中,利用存储卷的快照功能。
- 将备份流程自动化,并测试恢复操作。
- 安全与权限管理:
- 注意容器内进程的用户ID(UID)与宿主机文件权限的匹配,避免权限错误。可以在Dockerfile中用
USER指令指定非root用户运行。
- 对于敏感数据,考虑使用加密的卷驱动或在应用层加密。
五、
Docker的持久化存储和数据共享能力,是将容器技术成功应用于有状态服务和数据处理系统的基石。通过合理选择和使用数据卷(Volumes)、绑定挂载(Bind Mounts),并结合Docker Compose等编排工具,开发者可以构建出既具有容器弹性、可移植性优势,又能保证数据持久性、共享性和安全性的现代化数据处理与存储架构。始终牢记:容器应是临时的,而数据必须是永恒的。
如若转载,请注明出处:http://www.aijiasichu.com/product/39.html
更新时间:2026-06-18 19:15:05