数据科学入门系列课程 数据存储与计算、架构与选型全解析
整体流程与概念
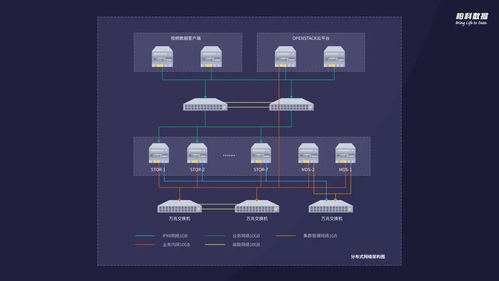
在数据科学中,数据存储与计算是核心环节。整体流程包括数据采集、存储、处理、分析和可视化。数据存储负责持久化数据,而计算则涉及数据处理、分析和模型训练。高效的数据管理能够提升数据科学项目的可扩展性和性能。
数据库的选型
选择合适的数据库是数据存储的关键。常见的数据库类型包括关系型数据库(如MySQL、PostgreSQL)、NoSQL数据库(如MongoDB、Cassandra)和时序数据库(如InfluxDB)。选型时需考虑以下因素:
- 数据结构:结构化数据适合关系型数据库,非结构化或半结构化数据适合NoSQL。
- 读写性能:高并发写入场景可选时序数据库或分布式NoSQL。
- 扩展性:云原生数据库(如AWS RDS、Google Bigtable)支持弹性扩展。
- 成本:开源方案(如PostgreSQL)可降低初期投入。
架构:Lambda vs Kappa
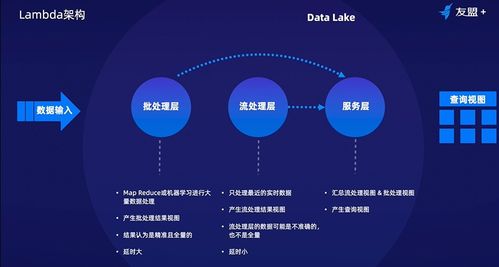
在数据处理架构中,Lambda和Kappa是两种主流设计模式:
- Lambda架构:结合批处理和实时流处理。数据同时流入批处理层(如Hadoop)和速度层(如Apache Storm),最终由服务层合并结果。优点是可处理历史数据和实时数据,但复杂度高。
- Kappa架构:简化版,仅依赖流处理。所有数据通过流处理引擎(如Apache Kafka、Flink)处理,无需批处理层。优点是架构简单、维护成本低,适合实时性要求高的场景。
数据处理和存储服务
现代数据处理和存储服务提供高效工具:
- 数据处理服务:如Apache Spark用于大规模数据处理,AWS Glue用于ETL作业。
- 存储服务:云服务如Amazon S3用于对象存储,Google BigQuery用于分析型数据仓库。
集成这些服务可构建端到端数据流水线,支持数据科学项目从原始数据到洞察的完整流程。
数据存储与计算是数据科学的基础,合理选型和架构设计能显著提升项目效率。建议结合实际需求,选择Lambda或Kappa架构,并利用云服务优化数据处理流程。
如若转载,请注明出处:http://www.aijiasichu.com/product/6.html
更新时间:2025-11-29 04:13:32