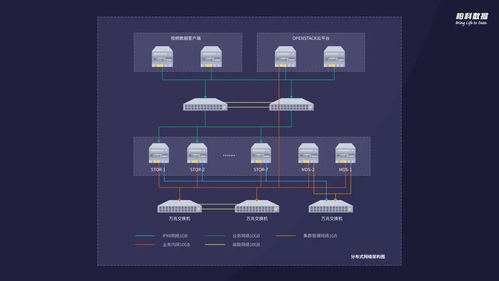
软件系统的数据存储设计 数据处理与存储服务的核心考量
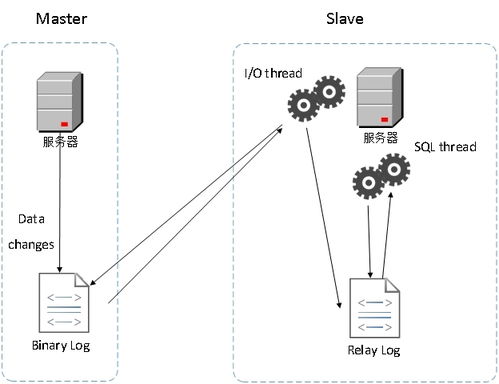
在当今信息化时代,数据已成为企业的核心资产,而软件系统的数据存储设计直接关系到系统的性能、可靠性和可扩展性。数据处理和存储服务作为系统架构中不可或缺的部分,其设计必须综合考虑业务需求、技术实现和未来发展的平衡。本文将围绕数据存储设计的关键要素,深入探讨数据处理与存储服务的设计原则及实践策略。
一、数据存储设计的基本原则
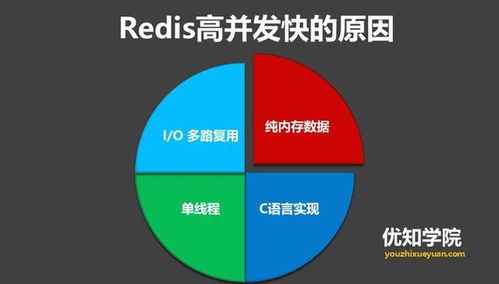
数据存储设计需遵循几项基本原则,以确保数据的安全性、一致性和高效性。数据模型设计应基于业务逻辑,合理划分实体与关系,选择适当的数据结构(如关系型数据库的表结构或非关系型数据库的文档/键值结构)。存储方案需考虑数据量、访问模式和性能要求,例如高频读写场景可采用内存数据库(如Redis),而海量数据分析则适合列式存储(如HBase)。设计应具备可扩展性,支持水平或垂直扩展,以应对未来数据增长。
二、数据处理的关键环节
数据处理是数据存储的支撑环节,包括数据采集、清洗、转换和加载(ETL)。在软件系统中,数据处理服务需要高效处理实时或批量数据流。实时处理可采用流式框架(如Apache Kafka或Flink),确保低延迟响应;批量处理则依赖MapReduce或Spark等工具,实现大规模数据的高效分析。数据处理需关注数据质量,通过去重、验证和标准化等手段,提升数据的准确性与完整性,为后续存储提供可靠输入。
三、存储服务的实现策略
存储服务的设计应围绕数据持久化、访问接口和容灾备份展开。关系型数据库(如MySQL、PostgreSQL)适用于事务性强的场景,保证ACID特性;而非关系型数据库(如MongoDB、Cassandra)则适合处理非结构化数据和分布式需求。存储服务需提供标准化的API接口,支持RESTful或GraphQL,便于系统集成。为确保数据安全,应实施定期备份、数据加密和异地容灾策略,防范单点故障和数据丢失风险。
四、综合考量与未来趋势
在设计数据存储与处理服务时,还需平衡成本、合规性和技术复杂性。例如,云原生存储服务(如AWS S3、Azure Blob Storage)可降低运维成本,但需考虑数据主权和合规要求。随着人工智能和物联网的普及,边缘计算和数据湖架构将推动存储设计向更分布式、智能化方向发展。设计者应持续评估新技术,保持系统的灵活性和前瞻性。
软件系统的数据存储设计是一个多维度工程,需从业务需求出发,结合数据处理与存储服务的技术特性,构建稳健、高效的解决方案。通过科学的设计原则和灵活的实现策略,企业能够最大化数据价值,支撑业务的持续创新与发展。
如若转载,请注明出处:http://www.aijiasichu.com/product/5.html
更新时间:2025-11-29 12:09:14